
This is a live audio stream generated by an ongoing software development project initiated in 2019, exploring real-time sonification of WiFi network activity.
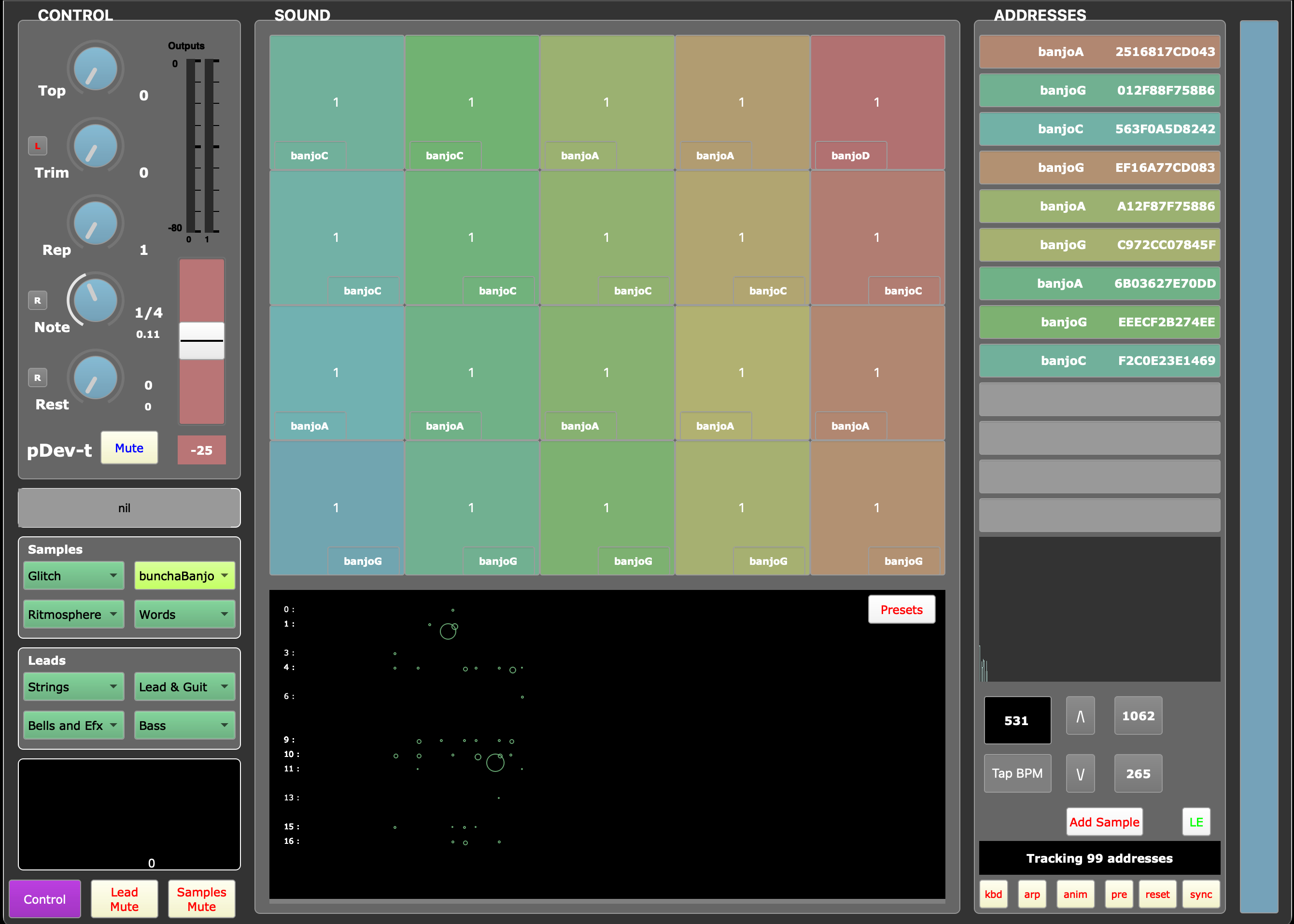
This system of distributed software translates WiFi network packets into sound, using MAC addresses as unique identifiers for audio generation. Each captured MAC “voice” is tabulated and assigned musical characteristics such as MIDI note values, and envelope parameters. The software organizes sample assignment to voices and the sequencing of notes within chord progressions. Audio parameters such as DSP and granular processing may be set by the user, or determined dynamically according to network parameters. This adaptive sound mapping allows network traffic patterns to influence the quality of audio output.
This portable system has been tested and optimized to operate across a variety of environments—from dense urban networks to sparse rural WiFi landscapes — each location producing a distinct sonic signature characterized by varying density and variability of network traffic. Networked versions of the system have been configured to play locally the patterns of voices captured from remote locales in conjunction with local voices.
This software has also been used to sonify datasets such as the genetic sequence of SARS-Cov-2 virus in a live, performance setting. In this case, data read from a list at a given rate would be assigned to note values or samples within the software and reassigned through the performance.
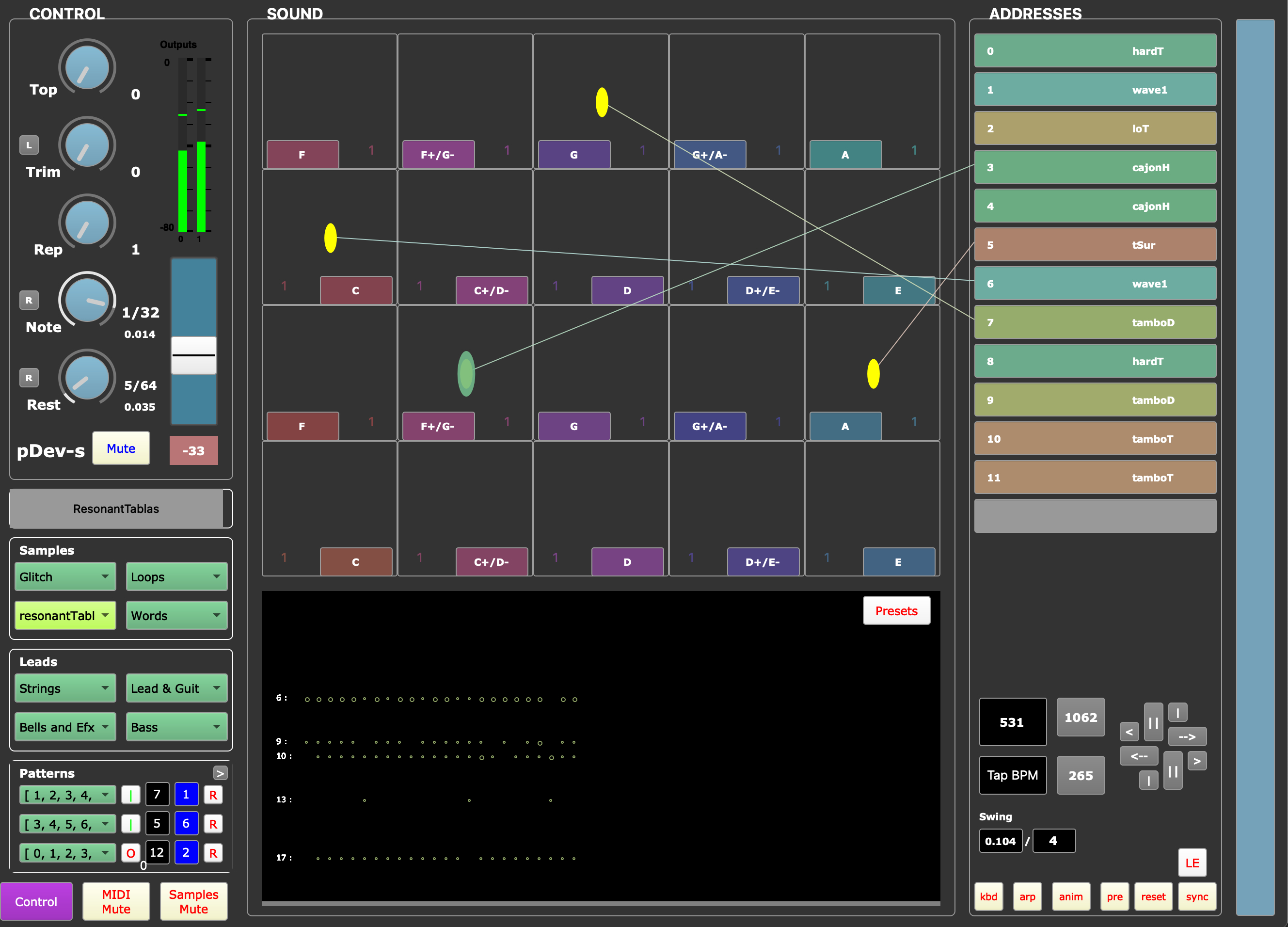
A complementary sequencer (a secondary version of the WiFi player) also contributes to the sound of this live stream. It’s tempo and varying note/rest/swing/sync durations are determined from dynamic analysis of WiFi traffic density.
The software is written in the SuperCollider programming environment. Mixdown is in Ableton Live before upload to this Icecast server for broadcast.
WiFi Player (2024/10)
Sequencer (2024/10)
News: (8/2)
Recent development includes work on an experimental programmatic means of creating titled audio tracks on the fly. As a desired broadcast stream sound is achieved, and an inspired title for the track is saved in a text file, a remote recording of 10 minutes of the stream is started. The audio file is saved automatically to an index of recordings, which are reloaded into the ongoing loop of recordings playing in the More section of the front page of this site. Eventually a listing of the titled recordings will be listed for individual listening, either here, or on another streaming platform.
Aesthetics: This live steam is usually unmanned 23 of 24 hours. As a work of experimentation and serendipity, a daily set-up is stabilized to degrade or to develop until a system crash (silence) or the next human intervention.